How to Choose a Continuous Integration Tool
I love continuous integration. Why?
- I’m forgetful.
- I break lots of stuff.
CI helps my forgetfulness in that it reminds me what needs to be done to build, test, run, and deploy the app.
CI helps my tendency to break stuff in that it stops my changes to getting to other teammates, or worse, production.
I’ve used a lot of CI tools and spent a lot of time trying many tools out: Bamboo, TravisCI, CircleCI, SnapCI, CodeShip, GitLab, Shippable, Concourse, Jenkins, and TeamCity. Despite this, I’ve really only scratched the service. The CI/CD tooling space is exploding. Stackify lists 50+ of them. Although it’s a bit overwhelming with so many options, it’s also super refreshing that we have so many options beyond that crusty Jenkins instance.
Here are some of my top 2017 criteria for evaluating a CI tool:
- SaaS: I don’t want to have to manage my own server for CI. I just want my CI to work. A lot of the code I write follows a serverless architecture (Serverless on Python) so it would just be silly to manage a server for the CI.
- YML: Because I’m forgetful, I want to open up a .yml file checked into my source control to see how the project works. If a new project has a CI configuration file it’s the first place I look (after a README.md) to see how things work. I’ve spend too many painful hours clicking through Jenkins UIs filling out text boxes and selecting radio buttons to know the CI configuration belongs in the codebase. I used SnapCI for a while which recently died in the ongoing CI tooling battle. It was an amazingly simple and powerful CI tool but the lack of a YML configuration was a major drawback. Every change had to go through the UI without any version control.
- Docker: I want the build, test, and deploy tasks to run in a predictable environment with specific versions of languages, libraries, and dependencies so there aren’t any surprises. By creating a base Docker image I can prebake the exact environment I want for the CI to run in. There’s a good chance I can start off with one of the bazillion Docker images already available on Docker Hub. If not I can upload my own with a simple Dockerfile. Prebaking the things that don’t change into the Docker image also can make the CI really fast.
- Pipelines: Each project is unique in the # of stages it needs in its pipeline. In order to deploy a new version of there may be some directed graph of:
- fast tests (to get feedback quick early in the pipeline)
- slow tests (to go more in depth with browser tests or integration tests)
- expensive tests (to see impact in performance at scale with high simulated loads)
- staging environment deployment (to enable manual exploratory testing or internal reviews)
- security gates (with tools like Snyk or Bithound)
- static analysis gates (with tools like Codeclimate)
- manual approval steps
- canary deployments to limit effects of something going wrong
- production environment deployment
~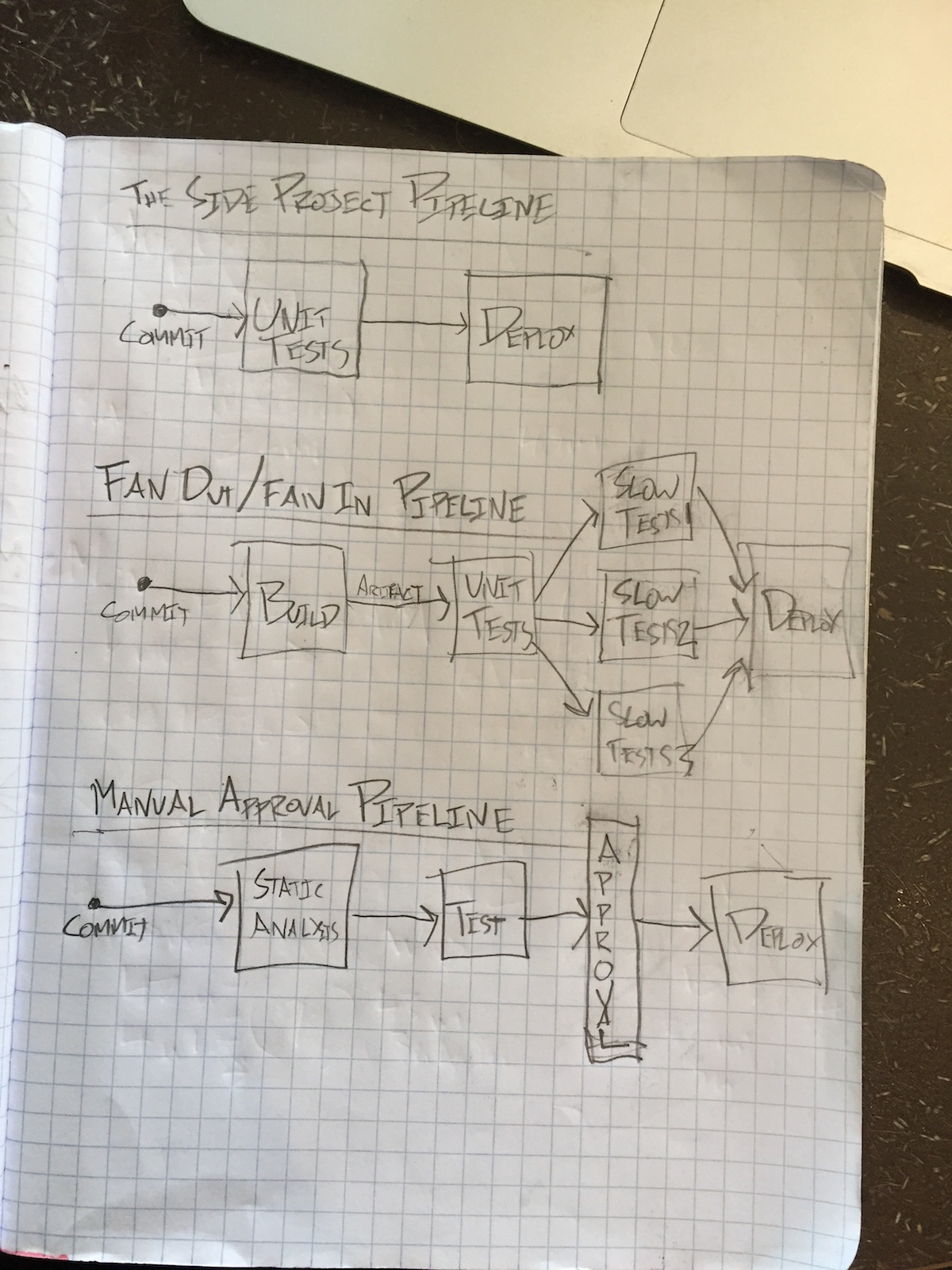
The pipeline should be unique to each project. It’s surprising to me how many services are out there today that market themselves as a “Continuous Delivery Solution” yet they have no ability to customize the CD pipeline. This filters out many tools as they lack the ability to add additional custom stages in the pipeline, run tasks in parallel, or allow for manual triggers mid-pipeline. The CD pipeline is just like other pieces of the code base, as the project matures and changes the CD pipeline will need to be refactored, iterated upon and expanded.
In my next post I’ll share my new favorite CI/CD tool that has really blown my socks off. It nails all of the criteria above and more. It’s that good. What criteria do you have in a CI tool? Are there any deal breakers for you?