Serverless Web Scraper with Change Notifications
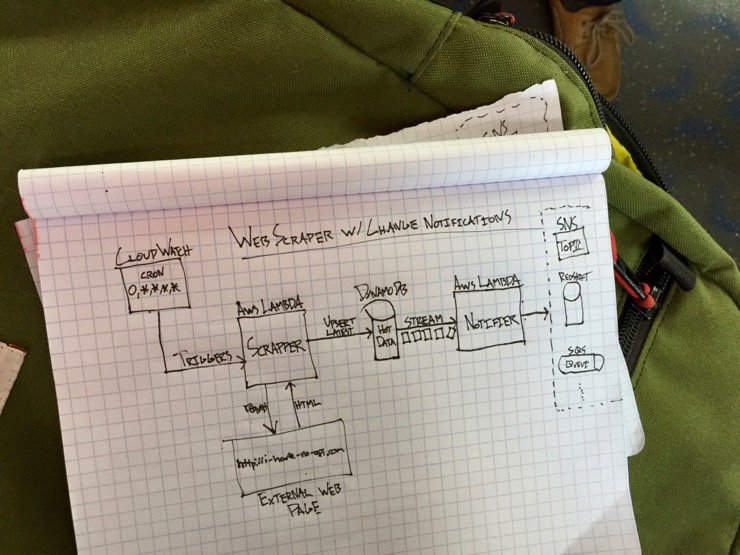 A scraper should run as infrequently as possible. It’s polling at its worst. These short-lived, infrequent requests make it a great candidate for Function-As-A-Service (FaaS) as it eliminate all the complexity and cost around running a server ourselves. For this post I’ll be in AWS land using the Lambda service and DynamoDB for auto-detecting changes to a website via scraping.
A scraper should run as infrequently as possible. It’s polling at its worst. These short-lived, infrequent requests make it a great candidate for Function-As-A-Service (FaaS) as it eliminate all the complexity and cost around running a server ourselves. For this post I’ll be in AWS land using the Lambda service and DynamoDB for auto-detecting changes to a website via scraping.
1. Create a Scraper Lambda Function
There are many libraries for making web scraping simple. In the web scraping function load up the HTML using any http request library and then parse via your preferred tool of CSS selectors, XPath or a higher level API (e.g. BeautifulSoup for Python or Cheerio for Node).
2. Cache the results in DynamoDB w/ DynamoDB Streams enabled
After extracting and transforming the data I load the hot data into DynamoDB replacing the stale scraped data. This is where the magic comes in. For any DynamoDB table a DynamoDB Stream can be configured to notify another AWS Lambda when data changes. There is no programmer effort required to detect changes between the stale and fresh data. Just load the fresh data into DynamoDB and the stream will notify the configured lambda if something changed. Slick.
3. Create a Notifier Lambda Function
When the DynamoDB stream notifies this lambda of a change event it can provide a snapshot of both the old and new data as inputs to the lambda by using the NEW_AND_OLD_IMAGES as the StreamViewType. Process the change event by comparing the diff and then notify by invoking subscribed webhooks, triggering an SNS Topic, storing the historical change events in a data warehouse, pushing it to a queue, etc.
4. Setup the CloudWatch Scheduled events
Now that all the pieces are there, the last thing to do is keep it all running autonomously by setting up a CloudWatch Scheduled Event (essentially a managed cron service) to trigger the scraper Lambda at a regular interval.